
Intorduce CSS/HTML Basics and Simple Python based CSS Parser
08/11/2021 Tags: Programming PythonPurpose
CSS (Cascading Style Sheets) and HTML (Hypertext Markup Languare) are two of the core technologies for building Web pages. CSS (cascading Style Sheets) is the language for describing the presentation of Web pages, including colors, layout, and fonts and the resendering of structured documents (such as HTML and XML). And, HTML represents the structure of the page.
The CSS parser is enabled to convert a CSS string to a data struct for HTML so that we could easily find the corresponding styles. In this post, I would like to go through the basic concepts of CSS/HTML and show the simple python css parser reworked from Simple CSS Parser.
Basic Concept of CSS
CSS is not a programming language and also not a markup language either. It is just a style sheet language for using to selectively style HTML element. For example, this CSS selects paragraph text, setting the color to red:
styles/style.cssp {
color: red;
}To apply above CSS to the HTML documents, you need to give the element a href attribute and link with the CSS style. Otherwise, the styling won’t change the appearance of the HTML.
<link href="styles/style.css" rel="stylesheet">
Anatomy of a CSS Ruleset
The whole CSS structure is called a ruleset, as shown below:
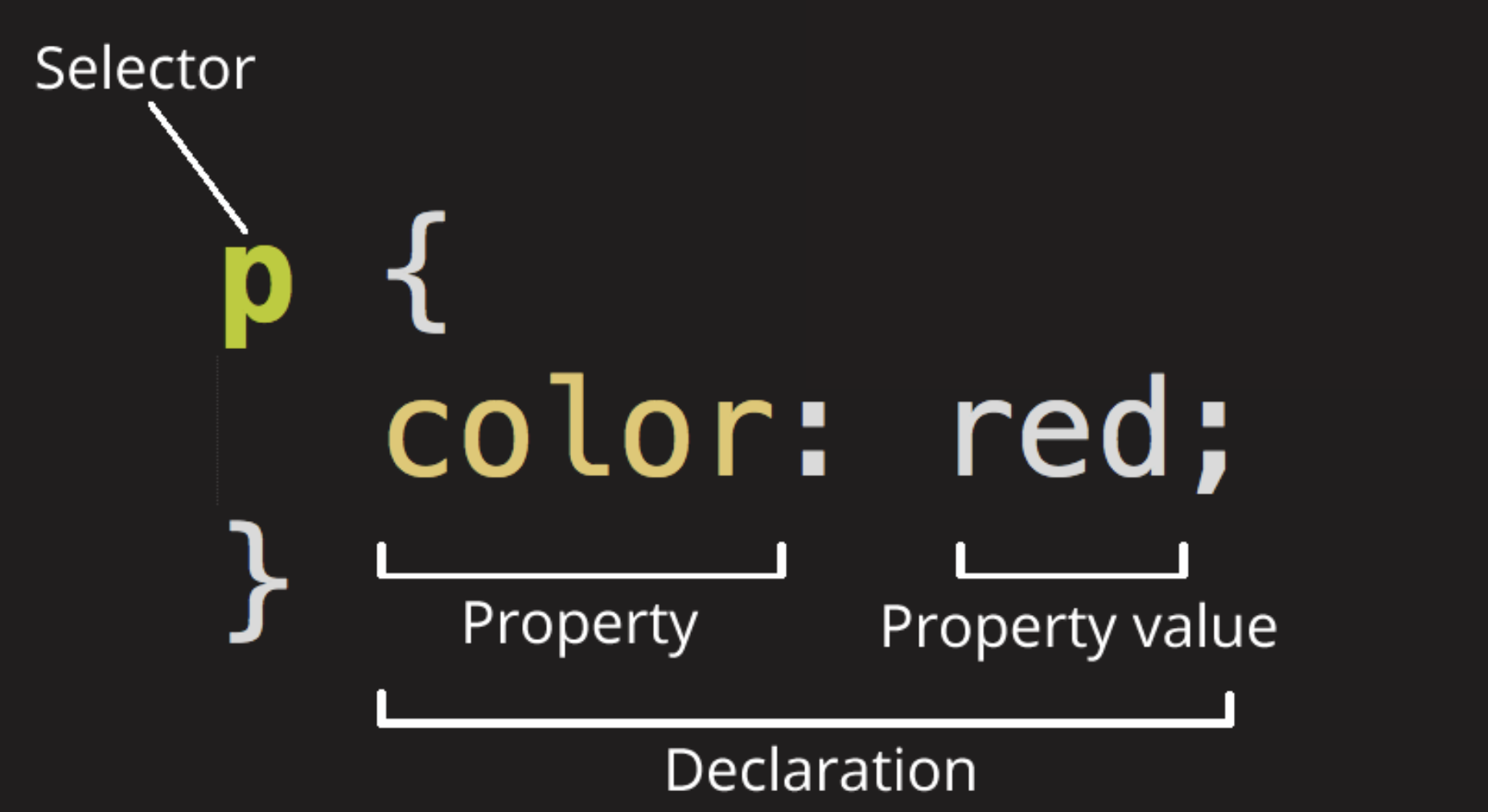
The main parts of this element are as follows:
- Selector: this is the HTML element name at the start of the ruleset. It defines the element to be styled.
- Declaration: This is a single rule. It specifies which of the element's properties you want to style."
- Properties: These are ways in which you can style an HTML element
- Porperty value: The chooses one out of many possible appearance for a given property.
Different Types of Selectors
A CSS selector is the first part of a CSS Rule. It is a pattern of elements and other terms that tell the browwe which HTML elements should be selected to have the CSS property and values inside the rule applied to them. There are many types of selectors. Here are some of the more common types of selectors:
| Selector name | What does it select | Example |
|---|---|---|
| Element selector | All HTML element of the specifies type | p selects <p> |
| ID selector | The element on the page with the specified ID | #my-id selects <p id="my-id"> or <a id="my-id">; |
| Class selector | The element on the page with the specified class. | .my-class selects <p class="my-class"> or <a class="my-class"> |
| Pseudo-class selector | The specified element(s), but only when in the specified state. | a:hover selects <a>, but only when the mouse pointer is hovering over the link |
You could find and learn more information from CSS selectors
Basic Concept of HTML
HTML is the language that is used to structure a web page and its content. The content could be structured within a set of paragraphs, a list of bulleted points, or using images and data tables. HTML consists of a series of elements. For example, we could specify a paragraph by enclosing it in paragraph tags:
<p>My cat is very grumpy<p>Anatomy of an HTML element
HTML cover elements, attributes, and other import terms, that can be applied to pieces of text to give them different meaning in a document. Here is an example of paragraph element:

The main parts of this element are as follows:
- The opening tag: This consists of the name of the element, wrapped in opening and closing angle brackets.
- The closing tag: This is the same as the opening tag, except that it includes a forward slash before the element name. Failing to add a closing tag is one of the standard neginner errors and can lead to strange results.
- The content: This the content of the elementm which in this case, is just text.
- This element: This opening tag, the closing tag, and the content together comprise the elemnt.
In addition, the elemnts can also have attributes that look like the following:

- The attributes: These contain extra information about the element that don't want to appear in the actual content.
Some Types of HTML Elements
HTML elements can be represented in other tpyes, such as nested, empty. Nested element could apply multiple HTML tags to a simgle piece of content. And, the empty element could be used for image element because an image element doesn’t wrap content to affect it.
# Nested element
<p>My dog is<em>very grump.</em></p>
# Empty element
<img src="images/firefox-icon.png" alt="My test image">For more information of HTML elements, you could learn from HTML elements reference.
CSS Parser
The Concept of Lexical Analysis
In computer science, the lexical analysis or tokenization is the process of coverting a seqenece of characters into a sequence of tokens (strings with an assigned and thus identified meaning). This process can be considered a sub-task of parsing input. A program that performs lexical analysis may be termed a lexer or tokenizer. A lexer is generally combined with a parser, which together analyze the syntax of programming language, web pages, and so forth.
A lexical token or simple token is a string with an assigned and thus identified meaning. It is structured as a pair consisting of token name and an optional token value. The token name is a catergory of lexical unit. Common token names are
| Token name | Description | Sample token values |
|---|---|---|
| identifier | names the programmer chooses | x, color, UP |
| keyword | names alreay in the programming language | if, while, return |
| separator | punctuation characters and paired-delimiters | }, {, ; |
| operator | symbols that operate an arguments and produce results | +, <, = |
| literal | numeric, logical, textual, reference literals | true, "music", 6.02e23 |
| Comment | line, block | /* Retrieves user data */ |
Here is an example of expression in the C programming language:
// A simple expression
x = a + b * 2;
// The lexical analysis of this expression yields the following sequence of tokens:
[(idnetifier, x), (operator, =), (identifier, a), (operator, +). (identifier, b), (operator, *), (literal, 2), (separator, ;)]
The lexical analysis needs two stages. The first stage, the scanner, is usually based on a finite-state machine (FSM). It has encoded within it information on the possible sequences of characters that can be contained within any of the tokens it handles. The second stage, the evaluator, which goes over the characters of the lexeme to produce a value.
You could learn more information about lexical analysis from Wiki: Lexical analysis
The Implementations of CSS Parser
There are many CSS parsers in java or in C or in C++, etc. In this post, I created the lite CSS Parser in python and further to generate an HTML template. The code was initially extracted from Simple CSS Parser and then reworked. But, the lite CSS parser only process four types of state, parsing in selector, parsing in property, parsing in value and parsing in comment. The basic functions for the CSS parser are a follows:
- Read a CSS file
- Store CSS in the Collection with different elements
- Query for the selector, property and value
- Turn the Collection with different elements into HTML
Here is a simple css format file and the corresponding Web converted by the lite CSS Parser repo. The best way to understand the parser interface is to excute main.py which is excerpted below:
main.pyfilepath = './simple.css'
parser = CssParser(filepath)
parser.write("test.xml", "xml")Simple css format/* General page style
General page style */
div {
width: 100px;
height: 100px;
background-color: lightblue;
}
div:hover {
width: 300px; /* test */
}The corresponding HTML<html>
<body>
<div>
<div>
<div:hover width="300px">Contents</div:hover>
</div>
<div>
<div width="100px">Contents</div>
<div background-color="lightblue">Contents</div>
<div height="100px">Contents</div>
</div>
</div>
<div>
<div>
<div:hover width="300px">Contents</div:hover>
</div>
<div>
<div width="100px">Contents</div>
<div background-color="lightblue">Contents</div>
<div height="100px">Contents</div>
</div>
</div>
</body>
</html>Reference
[1] CSS basics
[2] HTML basics
[4] Lexical analysis
Feel free to leave the comments below or email to me if you are interested in this topic or have any pieces of points. :)